注意:因为学习平台题目是随机,选择题选项也是随机,一定注意答案对应的选项,同学们在本页按“Ctrl+F”快捷搜索题目中“关键字”就可以快速定位题目,还是不懂的话可以看这个:快速答题技巧
青少年社交网络信息数据预处理
一、实验目的
1. 掌握数据清洗的典型流程和方法。
2. 掌握数据缺失值和异常值的处理方法。
3. 掌握特征编码和特征标准化的特征处理方法。
二、实验内容
随着 Facebook、Twitter等社交网络平台的流行,越来越多的青少年用户会在这些平台发布消息。请使用Pandas包和sklearn的预处理模块中的一些类,对青少年社交网络信息数据集进行预处理。
数据集teenager_sns.csv(见附件)是一份包含30000个样本的美国高中生社交网络信息。数据均匀采样于2006年到2009年,每个样本包含40个变量,其中gradyear、gender、age和friends四个变量代表高中生的毕业年份、性别、年龄和好友数等基本信息,剩余36个关键词代表了高中生的5大兴趣类:课外活动、时尚、宗教、浪漫和反社会行为。具体描述如下:
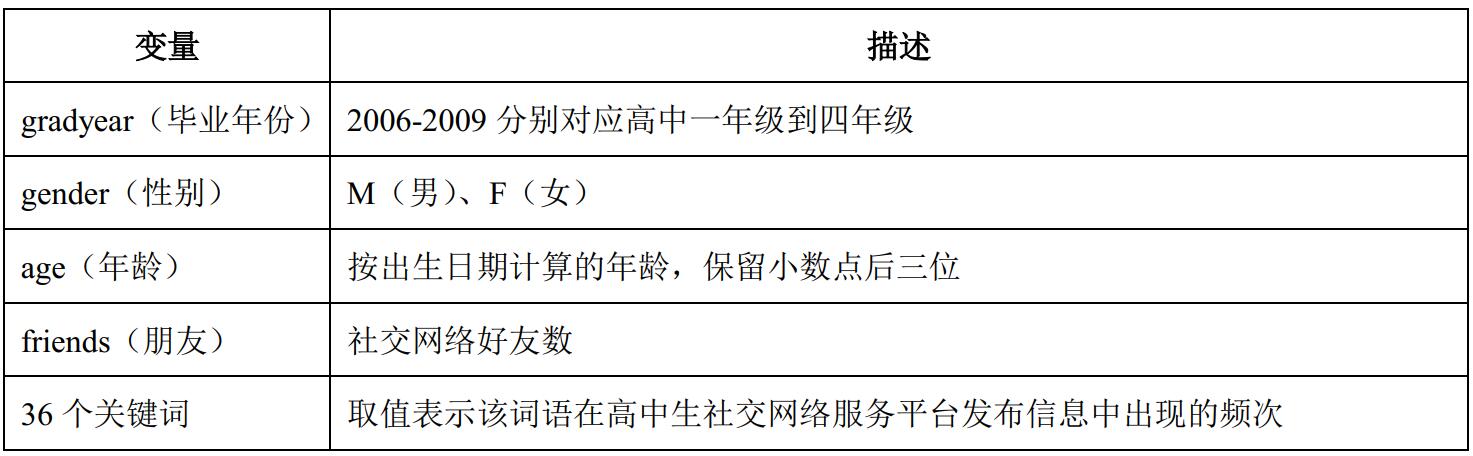

要求:
1. 数据读取与查看
(1)从本地读取数据,并查看数据的前5行。
(2)利用info()函数从宏观上查看数据集整体情况。
(3)观察数据集,查看gender和age两个变量是否存在缺失值。
(4)调用describe()函数进一步查看age变量整体情况。
(5)重新统计age缺失值数目(青少年的年龄限定在13-20岁)。
2. 缺失值处理
(1)使用sklearn中的Imputer方法,将数据集teenager_sns中age列利用均值进行填充。
(2)查看性别age一列的缺失值数量。
(3)考虑直接删除性别缺失值。
(4)检查缺失数据。
3. 异常值处理
(1)对friends列数据进行异常值检测。
(2)剔除friends异常值(大于100左右为异常值)。
(3)查看异常值剔除后的数据分布情况,重置索引。
4. 标准化
(1)使用sklearn中的StandardScaler方法,对friends列做Z-Score标准化,使得处理后的数据具有固定均值和标准差。
(2)使用sklearn中的MinMaxScaler方法,对friends列做Min-Max标准化,使得处理后的数据取值分布在[0,1]区间上。
5. 特征编码
(1)使用sklearn中的LabelEncoder方法,对gender列进行特征编码。
(2)尝试对gender一列进行One-Hot编码。(提示:在进行One-Hot编码前,需要先进行数字编码,M编为1,F 编为2,随后用One-Hot编码将1转换为(1,0),2转换为(0,1))
(3)使用sklearn中的Binarizer方法,对friends列进行二值特征离散化。
6. 离散化
(1)使用Pandas中的cut方法,实现friends列等距离散化。
(2)使用Pandas中的qcut方法,实现friends列等频离散化。
7. 数据保存
对预处理后的数据进行存储。
三、作业提交要求
完成实验报告(见附件模板),将源代码和实验报告一起压缩打包提交至学习平台。
 未经授权,禁止转载,发布者:形考达人
未经授权,禁止转载,发布者:形考达人 ,出处:https://www.xingkaowang.com/9704.html
,出处:https://www.xingkaowang.com/9704.html
免责声明:本站不对内容的完整性、权威性及其观点立场正确性做任何保证或承诺!付费为资源整合费用,前请自行鉴别。
免费答案:形考作业所有题目均出自课程讲义中,可自行学习寻找题目答案,本站内容可作为临时参考工具,但不应完全依赖,建议仅作为辅助核对答案的工具,而非直接使用!
