注意:因为学习平台题目是随机,选择题选项也是随机,一定注意答案对应的选项,同学们在本页按“Ctrl+F”快捷搜索题目中“关键字”就可以快速定位题目,还是不懂的话可以看这个:快速答题技巧
江苏开放大学数据采集与预处理第四次形考选择题
1、下列选项中,关于groupBy()方法说法不正确的是( )。
A、分组键可以是列表或数组,但长度不需要与待分组轴的长度相同
B、可以通过DAtAFrAme中的列名的值进行分组
C、可以使用函数进行分组
D、可使用series或字典分组
正确答案:A 学生答案:A
2、下列选项中,关于Agg()方法使用不正确是( )。
A、A、gg()方法中funC参数只能传入一个函数
B、A、gg()方法中funC参数可以传入多个函数
C、A、gg()方法中funC参数可以传入自定义函数
D、A、gg()方法不能对产生的标量值进行广播
正确答案:A 学生答案:A
3、下列选项中,关于trAnsform()方法说法正确的是( )。
A、不会与原数据保持相同形状
B、会对产生的标量值进行广播操作
C、funC参数只能传入内置函数
D、funC参数可以传入多个内置函数
正确答案:B
4、请阅读下面一段程序:
import pAnDAs As pD(pD.DAtAFrAme([,3],]*3,Columns=[‘A’,‘B’])).Apply(lA、mBDA x:x+1)
执行上述程序后,最终输出的结果为()。
A、A B032132232
B、A B02323223
C、A B034134234
D、A B043143243
正确答案:D 学生答案:D
5、下列选项中,关于A、pply()说法不正确的是( )。
A、可以使用自定义函数
B、可以接收多个函数
C、可以使用广播功能
D、返回的结果一定与原数据的形状相同
正确答案:D 学生答案:D
6、下列选项表述错误的是( )。
A、数据库可以通过降低数据的冗余度减小数据的存储空间
B、通过专有的操作语句,可以对数据库中的数据进行操作
C、数据库通常分为关系型数据库和非关系型数据库
D、关系型数据库具有高扩展性和高性能的优点
正确答案:D 学生答案:D
7、下列选项表述错误的是( )。
A、关系型数据库具有容易理解、使用方便、安全性能高等优点
B、非关系型数据库具有读写性能高、存储数据格式多样等优点
C、在数据量较大的情况下,关系型数据库在查询速度上通常不及非关系型数据库
D、非关系型数据库比关系型数据库安全性能高,而且提供多种数据存储格式
正确答案:D 学生答案:D
8、以下关于MySQL的说法错误的是( )。
A、.MySQL是一个开源软件。
B、.MySQL⾮常灵活,适⽤于⼩到中型的数据处理。
C、.MySQL是没有服务器的,不需要服务器进程或系统来操作。
D、.MySQL是一个跨平台的数据库系统: WinDows , MACOS , Linux 和 Unix 均适⽤。
正确答案:C 学生答案:C
9、关于MySQL中的数据类型,下列选项表述不正确的是( )。
A、.VARCHAR(length)表示最大长度 为length的可变长度字符串。
B、.TEXT表示最大长度为64KB的可变长度字符串。
C、.CHAR(length)表示最大长度为length的可变长度字符串。
D、.DATE和TIME都可以作为日期型数据。
正确答案:C 学生答案:C
10、下列哪个⼯具不能实现数据清洗功能?( )
A、ExCel
B、OpenRefine
C、WekA
D、photoshop
正确答案:D 学生答案:D
11、WekA使⽤什么编程语⾔进⾏开发?( )
A、C
B、C++
C、Python
D、JAvA
正确答案:D 学生答案:D
12、下列哪个选项不属于WekA集合的数据挖掘功能?( )
A、数据预处理
B、关联规则挖掘
C、搭建神经⽹络
D、数据可视化
正确答案:C 学生答案:C
13、OpenRefine的⼯作⽅式是?( )
A、单元格
B、图
C、列和字段
D、矩阵
正确答案:C 学生答案:C
14、OpenRefine不⽀持下列那种⽂件格式?( )
A、C、sv⽂件
B、tsv⽂件
C、json⽂件
D、py⽂件
正确答案:D 学生答案:D
15、在OpenRefine界⾯,下列哪个变量不属于 GREL 语⾔?( )
A、vAue
B、row
C、Cell
D、grAD
正确答案:D 学生答案:D
16、在OpenRefine界⾯,下列哪个选项能够查看数据集D、A、tA中是否含有缺失值?( )
A、DAtA.inDex
B、DAtA.vAlue
C、DAtA.Cell
D、isNull(DAtA)
正确答案:D 学生答案:D
17、下列选项表述不正确的是( )。
A、OpenRefine使用的是计算机的3333、端口
B、可以在命令行使用trl+C命令退出OpenRefine软件
C、可以在OpenRefine界面的LAnguAge Settings 选项处进行语言的选择
D、OpenRefine使用的是计算机的8000端口
正确答案:D 学生答案:D
18、下列选项表述不正确的是( )。
A、OpenRefine支持多种格式的数据文件
B、OpenRefine支持多种数据导入方式
C、OpenRefine支持撤销操作
D、GREL为OpenRefine的内建语言,不能与正则表达式结合进行数据转换
正确答案:D 学生答案:D
19、在openrefine的内建语言中,能将string s转换为小写的是( )。
A、stArtsWith(string s,string suB)
B、enDsWith(string s, string suB)
C、toUpperCAse(string s)
D、toLowerCAse(string s)
正确答案:D 学生答案:D
江苏开放大学数据采集与预处理第四次形考简答题
1、请简述常用的分组方式。
参考答案:
1.等距分组法:等距分组法是将数据按照一定的间隔划分为若干组,每组的数据范围是相同的。这种方法适用于数据变化较平稳、分布比较均匀的情况。例如,对学生的身高进行等距分组,可以将身高按照5厘米一个间隔进行分组,得到的数据组数较多,但每组的数据范围相同,方便进行比较和分析。
2.等频分组法:等频分组法是将数据按照出现频率的大小划分为若干组,每组的数据量相同。这种方法适用于数据分布不均匀、存在异常值的情况。例如,对班级成绩进行等频分组,可以将成绩按照出现频率的大小进行分组,这样可以排除异常值的影响,更加准确地反映学生的整体水平。
3.聚类分组法:聚类分组法是将数据按照相似性进行聚类划分为若干组,每组的数据具有较高的相似性。这种方法适用于数据类型比较复杂、不易按照单一指标进行分组的情况。例如,对消费者进行聚类分组,可以将他们的消费行为、生活方式、偏好等多个指标进行综合评估,得到不同的消费群体,为企业提供更加精准的市场分析和营销策略。
4.主成分分析法:主成分分析法是将多个相关指标进行综合分析,得到少数几个主成分来描述数据的变化情况,再根据主成分进行分组。这种方法适用于数据类型复杂、指标之间存在相关性的情况。例如,对企业的财务数据进行主成分分析,可以得到财务状况、盈利能力、偿债能力等主要因素,再根据这些因素进行企业排名和分组,为投资者提供更加精准的投资建议。
5.决策树分组法:决策树分组法是根据数据的特征和分类标准,通过构建决策树来进行数据分组。这种方法适用于数据类型复杂、分类标准多样的情况。例如,对消费者进行决策树分组,可以根据他们的性别、年龄、职业、收入等多个因素进行分类,得到不同的消费群体和消费偏好,为企业提供更加精准的产品定位和营销策略。
2、现有表DouBAn,表内有若干条出版社数据信息。 iD为出版社编号,puBlish_ nAme列为出版社名称,Book_numBer列为出版书籍数量,puBlish_ link为出版社链接网址。
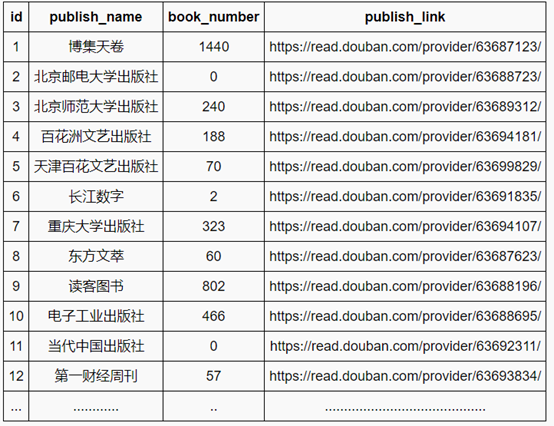

请使用seleCt和like语句查询出名字以北京开头的出版社名称( puBlish_ nAme)。并提交与判定SQL语句。
3、现有如下图所示的学生信息,请根据图中的信息完成以下操作:
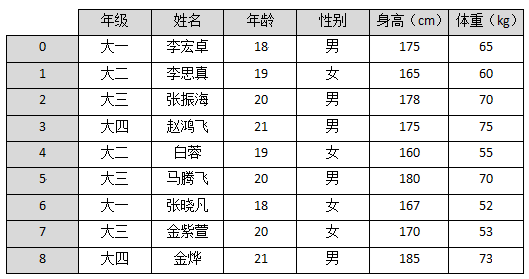
1、)根据年级信息为分组键,对学生信息进行分组,并输出大一学生信息。(18分)
(2、)分别计算出四个年级中身高最高的同学。(10分)
(3、)计算大一学生与大三学生的平均体重。(10分)
请将程序写在下面的文本框内。
students = [
{ 'name ':‘张三', 'grade ': '大一','height': 170,"weight': 60},{ "name ' : ‘李四', 'grade ': ‘大二',‘height ': 175,"weight': 65},{ 'name ': '王五', 'grade ': '大一', 'height ' : 180,"weight': 70},{ " name': ‘赵六','grade': ‘大四',‘height': 185,"weight ': 75},{ 'name ':‘钱七', 'grade': ‘大三:,‘height ' : 190,"weight': 80},{ ' name ': ‘孙八', 'grade': '大一', "height': 195,"weight ': 85},{ ' name': ‘周九', 'grade': ‘大三',"height': 200,"weight ' : 90},{ 'name ': ‘吴十', 'grade': '大二',"height ': 205,'weight ': 95},
#(1)根据年级信息为分组键,对学生信息进行分组,并输出大一学生信息。groups ={}
for student in students:
grade = student[ ' grade']if grade not in groups:groups[grade] - []
groups[grade].append(student)
for student in groups[ '大一']:
print( student)
#(2)分别计算出四个年级中身高最高的同学。
for grade in[ '大一',‘大二",'大三','大四']:
max_height = e
max_student = None
for student in groups[grade]:
if student[ " height' ] > max_height:
max_height = student[ " height ' ]max_student = student
print('年级:,身高最高的同学:{]}'.format(grade,max_student[ ' name']))
#(3)计算大一学生与大三学生的平均体重。sum_weight = e
count = e
for student in groups[ '大一']:
sum_weight += student[ " weight' ]count += 1
avg_weight_1 = sum_weight / count
sum_weight = e
count = 6
for student in groups[ '大三']:
sum_weight += student[ " weight']count += 1
avg_weight_3 = sum_weight / count
print('大一学生平均体重:{,大三学生平均体重:{}'.format(avg_weight_1,avg_weight_3))
 未经授权,禁止转载,发布者:形考达人
未经授权,禁止转载,发布者:形考达人 ,出处:https://www.xingkaowang.com/9700.html
,出处:https://www.xingkaowang.com/9700.html
免责声明:本站不对内容的完整性、权威性及其观点立场正确性做任何保证或承诺!付费为资源整合费用,前请自行鉴别。
免费答案:形考作业所有题目均出自课程讲义中,可自行学习寻找题目答案,本站内容可作为临时参考工具,但不应完全依赖,建议仅作为辅助核对答案的工具,而非直接使用!
