注意:因为学习平台题目是随机,选择题选项也是随机,一定注意答案对应的选项,同学们在本页按“Ctrl+F”快捷搜索题目中“关键字”就可以快速定位题目,还是不懂的话可以看这个:快速答题技巧
江苏开放大学数据采集与预处理第三次选择题
1、下列选项中,( )是评价数据质量的核心准则。
A、完整性
B、准确性
C、适用性
D、简洁性
正确答案:C 学生答案:C
2、下列说法中,关于清洗重复值的说法正确的是( )
A、清洗重复值的基本思想是“分而合之”
B、清洗重复值的基本思想是“排序”
C、清洗重复值的基本思想是“排序和合井”
D、清洗重复值的基本思想是“合并”
正确答案:C 学生答案:C
3、下列选项属于名义型特征的是( )
A、景点名称={天坛,北海,故宫、⾹⼭}
B、成绩={88,92,83,95}
C、质量⽔平={⼀级,⼆级,三级,四级}
D、半径={7.64,7.44,7.23,7.39}
正确答案:A 学生答案:A
4、下列选项中,描述不正确的是( )。
A、数据清洗的目的是为了提高数据质量
B、异常值一定要删除
C、可使用Drop_DupliCAtes()方法删除重复数据
D、ConCAt()函数可以沿着一条轴将多个对象进行堆迭
正确答案:B 学生答案:B
5、请阅读下面一段程序:
from pAnDAs import Series
import pnDAs As pD
from numpy import NAN
series_oBj = Series([None, 4, NAN])
pD.isnull(series_oBj)
执行上述程序后,最终输出的结果为( )。
A、0 True1 FAlse2True
B、0True1True2FAlse
C、0FAlse1True2rue
D、0True1 True2True
正确答案:A 学生答案:A
6、下列选项中,可以删除缺失值或空值的是( )。
A、.isnull()
B、.notnull()
C、.DropnA()
D、.fillnA()
正确答案:C 学生答案:C
7、下列选项中,描述不正确是( )。
A、ConCA、t()函数可以沿着一条轴将多个对象进行堆迭
B、merge()函数可以根据一个或多个键将不同的DAtAFrAme进行合并
C、可以使用renAme()方法对索引进行重命名操作
D、unstACk()方法可以将列索引旋转为行索引
正确答案:D 学生答案:D
8、请阅读下面一段程序:
import numpy As np
import pAnDAs As pD
ser_oBj = pD.Series([4, np.nAn, 6, ])
ser_oBj.sort_vAlues()
执行上述程序后,最终输出的结果为( )。
A、4、 -3、.0、5、 2、.0、0、 4、.0、3、 5、.0、 6、.01、 NA、N
B、1、 NA、N2、 6、.0、3、 5、.0、0、 4、.0、5、 2、.04、 -3、.0、
C、5、 2、.0、0、 4、.0、3、 5、.0、2、 6、.0、4、 -3、.0、
1、 NA、N
D、0、 4、.0、1、 NA、N2、 6、.0、3、 5、.0、4、 -3、.0、5、 2、.0、
正确答案:A 学生答案:A
9、下列说法错误的是( )
A、必须删除异常值
B、可以对缺失值进⾏插补
C、对数据进⾏标准化,消除量纲的影响
D、数据离散化是⼀种数据转换的⽅式
正确答案:A 学生答案:A
10、下列选项表述错误的是( )
A、数据清洗包括缺失值处理、异常值处理、数据转换等⼏个⽅⾯
B、数据的初步处理是对数据进⾏整合、分组等操作
C、检测异常值的⽅法可以基于统计、距离、密度、模型等
D、缺失值最好的处理⽅式是直接删除
正确答案:D 学生答案:D
江苏开放大学数据采集与预处理第三次填空题
1、常见的数据质量问题主要包括缺失值、以及错误值等问题。
正确答案:重复值
2、stA、C、k()方法可以将列索引转换为。
正确答案:行索引
3、技术是提高数据质量的有效方法。
正确答案:数据清洗
4、ConCAt()函数的堆迭方式有横向堆迭和,连接方式有内连接和纵向堆叠。
1、简述数据清洗的基本流程。
参考答案:
1、对缺失值进行清洗数据清洗第一步,对缺失值进行清洗。缺失值是非常常见的数据问题,它的处理方法也很多。下面分享一种很常用的方法,首先是明确缺失值的范围:对每个字段进行计算其缺失值比例,并按照缺失比例和字段重要性,分别制定策略。
2、去除不需要的字段:这个步骤非常简单,直接删掉即可。这里有一个点注意,就是记得先对数据进行备份,或者先进行小规模的数据实验,确定无误后在应用到大量的数据上。这样做是为了避免“一误删成千古恨”。
3、填充缺失内容:填充缺失数据有3种方法,分别是以业务知识/经验推测进行填充、以同一个指标计算的结果进行填充、以不同的指标计算的结果进行填充。
4、重新取数:重新取数是针对那些指标重要但缺失率又较高的数据,这需要向取数人员或是业务人员进行资讯,或者从其他渠道取到相关数据。
5、关联性验证:如果数据的来源较多,就有必要进行关联性验证。
2、现有如下图所示的两组数据,其中 A组中B列数据存在缺失值,并且该列数据为int类型,B组中的数据均为str类型。接下来,请对这些数据进行以下操作:
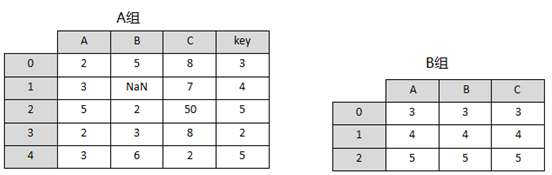

(1)使用DAtAFrAme创建这两组数据。
(2)现在需要使用B组中的数据对A组中的缺失值进行填充并保持数据类型一致。
(3)将合并后A组中索引名为key的索引重命名为D。
请将程序写在下面的文本框内。
import numpy as np
import pandas as pd
group_A=pd.DataFrame({'A':[2,3,5,2,3],
'B':[5,np.nan,2,3,6],
'C':[8,7,50,8,2],
'key':[3,4,5,2,5]},dtype=int)
group_B=pd.DataFrame({'A':[3,4,5],
'B':[3,4,5],
'C':[3,4,5]},dtype=str)
com=group_A.combine_first(group_B)
com.rename(columns={'key':'D'},inplace=True)
print(com) 未经授权,禁止转载,发布者:形考达人
未经授权,禁止转载,发布者:形考达人 ,出处:https://www.xingkaowang.com/9697.html
,出处:https://www.xingkaowang.com/9697.html
免责声明:本站不对内容的完整性、权威性及其观点立场正确性做任何保证或承诺!付费为资源整合费用,前请自行鉴别。
免费答案:形考作业所有题目均出自课程讲义中,可自行学习寻找题目答案,本站内容可作为临时参考工具,但不应完全依赖,建议仅作为辅助核对答案的工具,而非直接使用!
