注意:因为学习平台题目是随机,选择题选项也是随机,一定注意答案对应的选项,同学们在本页按“Ctrl+F”快捷搜索题目中“关键字”就可以快速定位题目,还是不懂的话可以看这个:快速答题技巧
爬取证券之星数据
一、实验目的
掌握使用urllib库访问目标网址,BeautifulSoup库解析网页,获得网页静态加载的数据信息的方法。
二、实验内容
创建一个爬虫项目StockStar,用于爬取证券之星的部分信息,主要包括代码、简称、流通市值(万元)、总市值(万元)、流通股本(万元)、总股本(万元),http://quote.stockstar.com/stock/ranklist_a.shtml,具体要求如下:
1. 使用urllib库、requests库访问网站,使用bs4库、lxml库解析网页。
2. 获取数据后,用NumPy库、Pandas库将其格式化为DataFrame
3. 用Python3自带的sqlite3库,将数据本地存储在数据库中。
4. 从数据库中读取数据并创建为DataFrame,再打印数据作为展示。
三、作业提交要求
完成实验报告(见附件模板),将源代码和实验报告一起压缩打包提交至学习平台。
解析网页
from bs4 import BeautifulSoup
import urllib
# 需要解析的目标地址
url = 'http://quote.stockstar.com/stock/ranklist_a_3_1_1.html'
# 访问目标地址
response = urllib.request.urlopen(url, timeout=60).read()
# 解析网页
soup = BeautifulSoup(response, 'html5lib', from_encoding='gb2312')
代码释义:
1.urllib.request.urlopen()函数实现对目标地址的访问
函数原型为:urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
其中,需要了解的有:
url:需要打开的网址
data:Post提交的数据
timeout:设置网站的访问超时时间
2.BeautifulSoup()函数实现对网页的解析
传入BeautifulSoup()一般需要3个参数:文档、解析器、编码方式。
将一段文档传入BeautifulSoup的构造方法,BeautifulSoup会将其解析,就能得到一个文档的对象, 可以传入一段字符串或一个文件句柄。
解析器可以自己选用,这里选用的是"html5lib",主要的解析器及其优缺点如下图所示:
推荐使用lxml和html5lib。另外,如果一段HTML或XML文档格式不正确,那么在不同解析器中返回的结果可能不一样,具体可以查看解析器之间的区别。
同时,urllib库可以用requests库替换,bs4库可以用lxml库替换,具体使用方法如下:
from lxml import etree
import requests
# 需要解析的目标地址
url = 'http://quote.stockstar.com/stock/ranklist_a_3_1_1.html'
# 访问目标地址
respond = requests.get(url).text
# 解析网页
tree = etree.HTML(respond)
代码释义:
1.requests.get()函数发送一个GET请求
函数原型为:requests.get(url, params=None, **kwargs)
其中,需要了解的有:
url:需要发送Request的对象地址
params:(可选)以字典形式传递参数
2.etree.HTML()从字符串中以树的结构解析HTML文档,返回解析后的根节点。
函数原型为:HTML(text, parser=None, base_url=None)
其中,需要了解的有:
text:需要解析成HTML文档的字符串
parser:传入参数以使用不同的HTML解析器
base_url:网站根地址,用于处理网页资源的相对路径
以上两种方式分别使用了urllib库→bs4库和requests库→lxml库。虽然使用的库不同,但是步骤都是先访问网页并获取网页文本文档(urllib库、requests库),再将其传入解析器(bs4库、lxml库)。值得一提的是,这两个例子中的搭配可以互换。
url = 'http://quote.stockstar.com/stock/ranklist_a_3_1_1.html'
response = urllib.request.urlopen(url, timeout=60).read()
tree = etree.HTML(response)
respond = requests.get(url).text
soup = BeautifulSoup(respond, 'html5lib')
如上所示:urllib库→lxml库和requests库→bs4库这样的方式也是可行的。
在目前的需求下,urllib库和requests库的差距体现不大,但是实际上二者还是有如下区别:
构建参数
urllib库在请求参数时需要用urlencode()对参数进行编码预编译,而requests库只需要把参数传入get()中的params中
请求数据
urllib库需要拼接一个url字符串,而requests库只需要将get()中的base_url填写完善即可
连接方式
urllib库每次请求结束关闭socket通道,而requests库多次重复使用一个socket,消耗更少资源
编码方式
requests库的编码方式更加完备
bs4库和lxml库的对比
一提到网页解析技术,提到最多的关键字就是BeautifulSoup和xpath,而它们各自在Python中的模块分别就是bs4库和lxml库。以下是它们的区别:
效率
一般来说,xpath的效率优于BeautifulSoup。BeautifulSoup是基于DOM的,会载入整个文档,解析整个DOM树,因此时间和内存开销都会大很多。进行分步调试时,生成soup对象时会有明显的延迟。lxml.etree.HTML(html)在step over的一瞬间便成功构建了一个可执行xpath操作的对象。并且lxml库只会进行局部遍历。
难度
个人认为bs4库比lxml库更容易上手。一方面是使用门槛,BeautifulSoup中的各种方法,看了文档就能用;而lxml需要通晓xpath语法,这意味着需要同时学习xpath语法和查询API文档。另一方面是返回结果,lxml中的xpath()方法返回对象始终是一个list,处理起来比较尴尬;而BeautifulSoup中的方法相对灵活,适合不同场合。
适用场合
这里主要提一下使用禁区。当遇到list嵌套list的时候,尽量不选择BeautifulSoup而使用xpath,因为BeautifulSoup会用到2个find_all(),而xpath会省下不少功夫。当遇到所需获取的类名有公共部分时,可以使用BeautifulSoup而非xpath,因为xpath需要完全匹配,也就是除了公共部分之外各自独有的部分也得匹配,这样就需要多行代码来获取,而BeautifulSoup可以仅匹配公共部分就获取所有匹配上的类。
3.2 获取数据
在本案例中,所有由bs4库获取的内容都可以用同样的逻辑思路用lxml库获取,因此将用bs4库先作演示如何获取内容,再直接根据bs4库提到的标签,直接写出lxml库的代码。
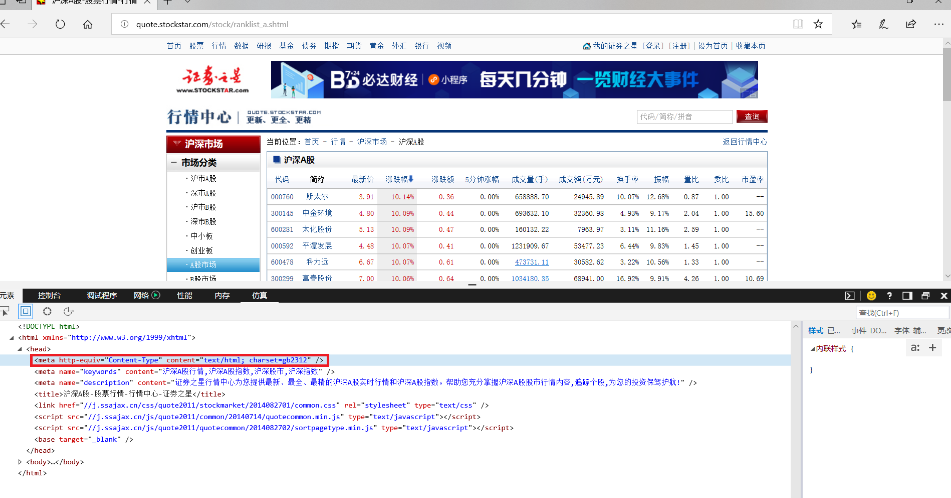

通过查看网页源码可以看到,该网页并没有使用常见的”utf-8″编码,而使用了”gb2312″编码。
更多原文:Python证券之星数据爬取
本页面参考范文仅供参考,转转请注明出处:https://www.xingkaowang.com/9693.html
本文意在促进知识的共享与交流,提高公众对相关领域的认知和理解。
